http协议接口简单概括接口相对复杂的一个接口示例
2021-10-31
谢谢你的邀请
这里只讨论传统的http协议接口,不考虑各种类库提供的面向对象接口的简单总结
简单的界面示例
一个相对复杂的界面示例
[
[
'name' => 'cat1' ,
'age' => 2 ,
] ,
[
'name' => 'cat2' ,
'age' => 5 ,
] ,
[
'name' => 'cat3' ,
'age' => 2 ,
] ,
] ,
'code' => 1 ,
'msg' => 'the API!' ,
]);
上面一个比较复杂的接口例子有三个字段,data、msg、code。这是一个相对基本的最佳实践解决方案。实际过程可能会更复杂,返回的数据可能只有这个。
{
"data" : [
{
"name" : "cat1",
"age" : 2
},
{
"name" : "cat2",
"age" : 5
},
{
"name" : "cat3",
"age" : 2
}
],
"code" : 1,
"msg" : "success"
}
需要注意的是,在任何情况下,一旦确定了同一接口的规范,除非该接口关闭且不提供http服务,否则任何情况下都必须返回符合该规范的数据。如果服务器异常,则无法返回。正常数据,可以通过code和msg字段告知原因,方便前端调用者自行判断处理
对于数据字段,这个数组的数据来源大致如下:
")
json和xml的比较
json之所以比xml应用更广泛,是因为它的结构化描述数据更轻,使用的字符数更少,更节省网络资源。
传递相同的数据
json:
{"code":1,"msg":"the API!"}XML:
1
the API!
json格式表示键值对,而xml格式可以表示键值对以及属性特征
")
所以严格来说xml和json不能绝对同等转换,但是可以自定义规范使用json来表示xml的同义,即xml中的属性特征。json 中没有等效的表示
下例中ui:标签中的属性需要用类似json中@的方式来描述,可以实现和xml一样的数据传输,但是要明白本质是不等的
XML:
Search
json:
{
"@attributes" : {
"layout" : "vertial"
},
"block" : [
{
"@attributes" : {
"width" : "200",
"layout" : "horizontal"
},
"input" : {
"@attributes" : {
"value" : "Search"
}
},
"button" : "Search"
},
{
"@attributes" : {
"width" : "400"
}
}
]
}一般规格
该领域的设计规范没有特别的标准,通常是为了确保在一个项目或一个团队中的一致性
")
但这还远远不够。为了有一套规范,可供行业内不同团队、不同项目使用,一些大公司编写了通用规范。如果他们都遵守,沟通起来会更方便,减少分歧。项目中的沟通成本
前面说了,因为xml几乎已经被json取代了,这个协议几乎成了一个传说,个人觉得没必要学
这是一套比较复杂的规范,它带来的好处是它在规范内的表达能力非常突出。
通俗地说,现在我想用php,或go,或javaphp接口开发,或任何语言,调用另一个用php,或go,或java,或任何其他语言编写的函数或对象方法。如何实现?是的,不管你用什么语言,只要你在编码中遵循这套规范,那么你就可以达到这个要求
这个规范是soap的json版本,但它不仅是对数据传输的打包方式的替代,而且它的规范比soap的内容简单很多,所以优点是使用起来非常灵活,而且数据传输过程节省了网络资源。建议学习
另外php接口开发,还有一个比较时髦的东西叫,详情请看这里
WEB开发中,使用JSON-RPC好还是API好?
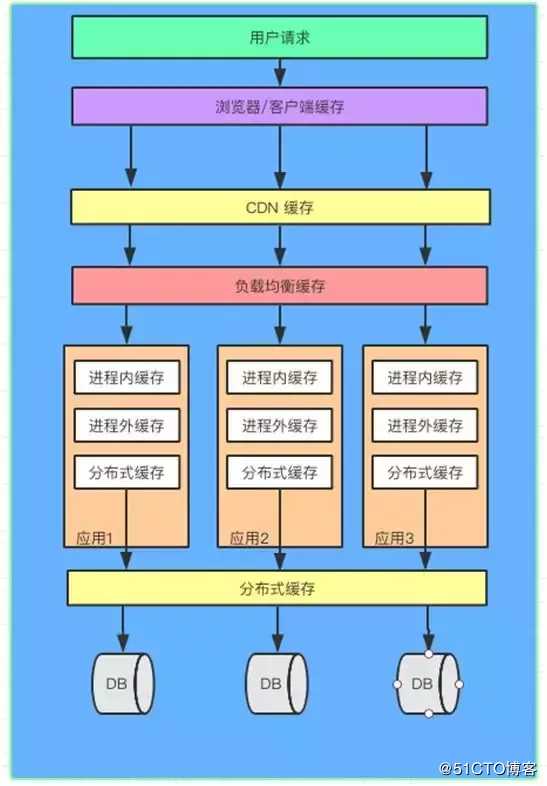
谈谈缓存
")
在讨论这个问题之前,我们首先要了解一件事,就是获取我们需要的数据时服务器开销的大小。
上面我们提到,大部分数据来自数据库,或者第三方接口返回的数据,听起来还可以,但遗憾的是这两种获取数据的方式都会有比较大的性能开销。
在数据库中查询时,数据库会操作硬盘,这对系统来说是一个很大的开销,尤其是在查询连接表时,开销几乎呈几何级数增长。
请求第三方接口时,会发送网络请求。如果对方接口有频率限制或者网络环境不稳定,会直接导致接口稳定
当然,我们的开发不会有任何“慢”或“卡”的感觉。毕竟对于人来说,0.01秒和0.秒基本没有区别,但是如果考虑并发,当一个操作重复1w、10w次的时候,这个开销是必须要考虑的,所以必须考虑缓存
前面提到的缓存方法(、、、、、DB、、H2等)都有一个共同的特点,就是读取其中数据的系统开销比之前的数据库或者第三方库或者其他方法要小。通常的做法是将数据直接存储在内存中。读取过程不需要操作硬盘,直接从内存中读取。因此,速度和成本都优于以前的方法。鉴于此,必须考虑缓存
是不是所有的接口都需要缓存?不必要。
通常最基本的原则是不经常变化的数据需要考虑,而经常变化的数据需要专门评估
通常最基本的做法是在接口逻辑中先读取缓存数据,如果没有读取缓存数据,则请求数据库,如果数据请求成功,则先缓存数据,然后返回数据
下次请求此接口时,将首先读取缓存。这时候上次缓存的数据已经在缓存中了,直接从缓存中取出数据返回。这样就避免了对数据库的请求,达到了减轻数据库压力的目的。
这种逻辑导致的问题是,更新数据库中的数据时,需要使相应的缓存失效。如何掌握使相应缓存失效的时机是一个比较重要的知识。通常,更简单粗暴的做法是指定缓存过期时间。在要求较高的系统中,需要特殊的方式来处理,这里不再赘述。
原谅我偷懒,这篇文章值得参考
Star Boy:缓存穿透、缓存崩溃、缓存雪崩原因+解决方案
常用的有,,,, DB,, H2等。
其中是纯内存缓存,不能持久化数据,可以缓存的数据类型比较有限,性能也是最优秀的
支持更丰富的数据类型,数据可以持久化到硬盘,建议考虑
其他未实战使用的缓存软件暂不评论
以上