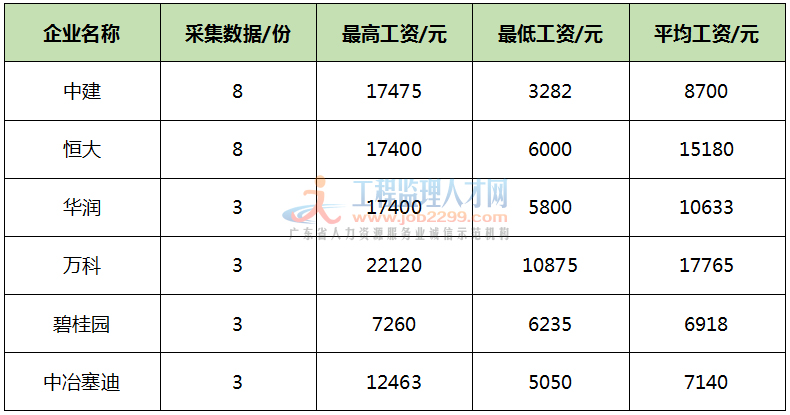
php订单管理系统 开源沈金堤:滴滴在数据库层面的实践(上)免费开源php cms系统
2022-06-03
● 在滴滴练习
● 我们使用更多的开源数据库
● 尝试整合数据库
● 考虑集成数据库实践的入口
文章摘要:
经过多年发展,已成为开源数据库中最重要的产品,拥有成熟的应用场景和生态工具。在实践的过程中,使用不同的存储技术来处理不同领域的问题也是共识,因此诸如 、 、 等产品也被应用到了不同的生产线上。过去,工程师需要将数据写入各种存储系统,不仅增加了技术实现的难度,也增加了相应的成本。现在,通过围绕结构化数据做ETL,只需要更新数据并将数据分发到不同的存储服务。单元化、同城双活等场景变得更加自然和简单。本次分享将数据库与周边生态工具整合的实践。通过开源协作,围绕中心的融合数据库技术将大大降低企业使用开源数据库的成本。
文字语音:
大家好,我叫沉金迪,来自滴滴出行网站开发,主要服务于基础设施团队和滴滴云产品技术团队。今天给大家分享滴滴在数据库层面的实践。如今,滴滴的整体规模和体量都比较大。如何以低成本快速提高效率,实现业务目标,成为了技术团队的核心价值。
“融合数据库”是我今天要分享的话题。一开始我觉得这个话题可能有点太大了,但我又想,我想和大家分享这个观点。因为滴滴从一家比较小规模的互联网公司成长为一家快速成长的互联网公司,也向很多腾云网络学习,学到了很多技术经验和知识。
一.在滴滴实习
滴滴现已在所有核心业务场景中使用。订单、付款、余额等都放在里面,非常安全。为什么安全?因为我们有专门的运维和研发团队,所以我们花了一年时间将5.5、5.6版本全面升级到5.7。虽然我们也在关注 5.8,但 5.7 将作为基准版本存在很长时间。
我们在这方面做了一些非常有趣的实践。现在云服务已经很成熟了php订单管理系统 开源,大家都习惯用RDS了,所以我们的工程师第一天就问有没有RDS的产品可以用。老实说,一开始并没有这样的事情。 2015年,我们开始组建RDS团队,希望将云服务和基础设施即服务的理念带到滴滴的整个基础设施建设中。因此,它是我们制作的第一个基础设施服务产品。
我们的数据库研发+中间件+自动化运维团队大概3到4人,当然也会有DBA支持,基本实现了所有工程师的自助服务,大约95%的工单自动完成,经主管批准并经DBA确认后自动执行。
我们在国内外的所有流程都是一致的,几乎都是基于,例如备份、监控、配套设施都进行了改造,除了数据库部分或者物理机的混合部署。滴滴的目标是在一两年内实现全平台容器化。当然,这个目标的实现也是具有挑战性的,因为滴滴有大量的代码模块,尤其是在数据库层面,要实现容器化还有很多问题需要解决。
一年前,我们团队解决了IO隔离、稳定性等一系列问题,接下来我们将着手整个数据库的迁移工作。
目前,滴滴的日均订单量为3000万,在中国的订单量相对较高。峰值订单为每秒 60,000 个。这个数值可能无法与阿里相提并论,但我们的复杂性也不在于订单数量,而在于如何在庞大的乘客需求和司机容量之间找到最合理的订单。
以下是滴滴实践中的一些情况。
整个用户控制台包括DDL权限管理、SQL异常统计、审计、黑名单等。相信做过DBA运维工作的朋友都觉得申请数据库白名单的繁琐,而我们通过API和白名单将所有的服务和组织结构序列化,工程师只要发布应用自然就可以访问自己的数据库.
我们有一个前端和两个工程师做自动化运维控制台,所以DBA有更多的精力专注于数据验证和机房搬迁。
上图是一个简单的数据结构,分为三个场景:在线业务系统、在线辅助系统和自动化运维系统。滴滴从一开始就考虑了分库分表,这是由顺序决定的。在单台机器上存储如此大量的数据更具挑战性。
所以从一开始,我们就有两名工程师专门负责维护开发工作。数据库是标准的一主双从结构,MHA切换,在分库分表的情况下我们也做了一些有趣的能力实现二级索引;类似的备份、审计系统、慢日志等由辅助业务系统实现;并将自动化运维系统开发设计为云产品。
做一个好的中间件是现在数据库的核心。如果没有中间件,未来很难进行自动化运维、扩容,甚至业务功能。比如主从有延迟,读写分离是很自然的场景,但是有些业务不能容忍延迟。如果读备库,会出现一致性问题,所以在中间件层面,我们会在SQL前加注强制读取主库,解决一致性问题,然后再读取从库进行其他企业。而如果没有支持,审计自动化运维将会带来巨大的挑战。
此外,滴滴还有几个关键能力,比如内置二级索引、单元化等,单元化在滴滴的应用比较明显。现在滴滴既有国内业务,也有国外业务,这两个业务的数据是完全隔离的。我们用一套代码和一套技术来实现国内业务。与国外平行。下一步,我们将在中国实行单元化,整个业务南北拆分。北方用户的订单数据放在北方机房,南方用户的数据放在南方机房。
二.我们使用更多的开源数据库
滴滴的每个产品都有一个用户控制台,所有的基础设施服务都得到了彻底的实现,从数据库服务发现到缓存消息队列再到长链接,只要你想得到所有的自助服务。我们希望整个运维效率能够大大提高,人工干预和决策减少。
我们仍然使用集群作为离线场景和MIS场景,但正在朝着主存储的方向发展。目前,主营业务也在使用。这是因为它的多维索引非常有用,工程师可以使用它。也比较容易,规模大概在几千左右。
主流的开源数据库都在使用中,如,、、、、、。除了标准的关系型数据库,还有两个不同场景的自研系统。一种是我们用来存储功能引擎,例如订单、驱动程序等。
DiDi 在早期被大量使用。工程师通常将其用作存储服务而不是缓存服务,但这给滴滴带来了很多麻烦。在数据量特别大的情况下,一台机器只能存储几百G。于是,又引入了另一个系统——基于。系统实现了跨机房的单元化和一致性,我们的核心数据也在尝试使用自研引擎提供服务。
滴滴现在都是开源的,从数据库层面到编程语言再到框架等等都是开源实现的。我们热爱开源,会回馈开源,未来系统也会开源。
三.整合数据库的尝试
为什么分库分表的情况下需要做二级索引?比如集群中有key,使用 ID创建分库分表。如果要查询乘客或司机的订单怎么办?工程师认为再建一个索引就够了,但是分库表就很难了。 所以工程师花了很多精力写了两张表,先写订单数据库,再写司机索引,再写乘客索引。这还不够,MIS还需要用到一、的两个维度。工程师写的大部分代码都是为了保证所有索引都写成功,但是有时候发布的时候数据会丢失。这个问题困扰我们很久了。
这个问题当然可以通过分布式事务产品在技术上解决,但是使用起来有点麻烦,所以我们从另一个维度进行了尝试。假设还有订单ID和乘客ID两个维度,我们实现了一个克隆系统php订单管理系统 开源,从主库更新完所有数据后,复制到另一个表。逻辑自动完成,相当于创建表时创建索引,分库分表的情况下创建主键,索引键的情况下自动将数据复制到另一张表中查询中自动识别,直接查询。
这对工程师来说是一种极大的解放。一个表中的两个索引也可以工作。当然,这也有局限性,但至少解决了写两张表的问题。这是我们基于 的第一次尝试,解决了很多业务问题,大大降低了整体代码复杂度。
第二次尝试是与 ES 的集成。上图是典型的架构图,业务代码是from to。其中,我们使用了阿里巴巴开源的中间件。我们将数据同步并写入 ES。
这样做的好处是在ES中建表,可以做到分钟级甚至秒级的数据查询,体验非常好。但是也会有问题。我们的代码大部分是 PHP 和 Go,所以工程师会觉得提供一个协议 ES 查询引擎很麻烦。
正因为如此,YASE引擎诞生了,它支持通过去访问ES。我们曾希望一切都是门户,但结果证明这不是一个好的解决方案。因为ES API的原生客户端和访问协议各有优势,灵活性和定制性更强。如果降级为标准的SQL协议,会损失很多能力,得不偿失。
四.我想入口的融合数据库
于是我们开始尝试整合数据库,最典型的就是业务代码会同时写,或者ES。大多数公司依次将数据写入每个数据库。写完,产品还是很多的。比如我们虽然只有两个从库,但是应用还是很多的,比如,YAES等。
写入各种克隆系统和异构存储系统也给运维带来很多麻烦。 DBA 认为光是运维就够复杂了。同步多个副本。
于是我们想出了一个新思路,在层级屏蔽一切,只提供一个服务,全部消费给 DDMQ。 DDMQ是基于阿里巴巴实现的带有事务的MQ引擎,至少可以消费一次消息队列。预计2018年完成DDMQ的完全开源。
我们把一切都和DDMQ集成在一起,也就是说,我们可以直接向DDMQ发送消息,这实际上是一个升级版。因为有DDMQ的存在,我们整个延迟,包括事务性,都有很大的保障。
同时,在此基础上,我们实现了DDMQ的ETL工作。滴滴目前的ETL工作还比较原始,但是我们的一些业务线已经开始尝试使用规则引擎来实现ETL工作。如果验证通过,会快速切换到顶部,并通过DDMQ将数据同步到ES,应用程序不需要实现写入。有多个副本。看来业务工程师只写一张表就可以访问多个数据源,整个访问方式并没有改变。
接下来介绍融合数据库的场景。
第一个是克隆系统。二级索引值只写一次,但是可以支持很多索引,但是也需要限制,因为如果索引太多seo优化,会影响整个延迟。索引不是问题。
第二个是缓存反冲。我们的很多代码都是 PHP 代码。它有一个特点,可以随时杀死。一旦被杀掉,缓存可能会更新失效,业务代码对缓存的依赖很重。如果没有事务缓存更新,工程师会写越来越多的代码。
第三个是单元化,跨机房和大洲同步数据。 2017年,滴滴开始国际化,2018年正式启动南美和北美国际业务。我们使用这项技术进行数据同步。从南美到北美的数据迁移是自动化的。北美数据室跑起来,自动完成数据复制,边写边复制。时间一到,就按城市切分。
第四个支持ES索引,MIS数据更新延迟到第二级;
第五次实时数据同步,所有表实时复制到HDFS。去年,我们的方法是在 12:00 开始拉数据库。拉完之后,整个数据中心都很热闹。但是现在数据最快可以统计到12:00。整个数据计算时间大大减少,但是为了保证数据的可靠性,我们在数据的校验和可靠性上花费了很多精力。
以实时业务监控为例,滴滴每天可能有 20 到 3000 万个订单,你怎么知道一个城市的交易量是同比下降还是上升?我们在DTS平台上连接了实时监控和实时消费,实时分析,非常低的延迟,几秒就能知道交易是否掉线了。
我们有一个 as 的概念,它涵盖了 OLTP 和 OLAP 场景。我们的目标是为入口写一条数据,有多种访问形式。
上图是我们对DTS的理解,形成了一种融合的存储服务。 DTS也在不断演进中,下一个目标我们希望用规则和脚本来实现ETL。在OLAP大数据场景中,我们使用过。在实时链路层,我们也分享了如何做实时大数据同步。除了数据库问题,我们还解决了一些日志问题……我们热爱开源,拥抱开源,也乐于分享。